- Analysis of Fast DCT, N=8
- Implementation of 8x8 DCT Algorithm using ARM NEON Assembly on RaspberryPi2
Preface —The Discrete Cosine Transform, DCT forms a major backbone behind Image processing and Video Encoding/Decoding Applications. The DCT/IDCT Algorithm is a form of Similarity Transform. This paper tries to analyze and discuss the motivation behind the development of the Fast Discrete Cosine Transform Algorithm based on Chen, Fralick et al, 1977[2], and C. Loeffler, Ligtenberg’s Practical Fast 1D DCT Algorithms, 1984[3]. Techniques of Matrix Decomposition based on Folding, Rotation Matrices and Jacobi Diagonalization have been used to analyze the Decomposition. Further, a proof of concept is presented in the form of a handwritten optimized, Assembly Language implementation in ARM NEON Assembly is presented. This greatly optimizes the performance and improves processing.
I. Introduction
The DCT is used extensively in Image and Video Encoders/Decoders. The DCT has a unique ability to pack the energy of the spatial sequence into as few frequency coefficients as possible. This helps us to transmit a few coefficients instead of the whole set of Pixels. The DCT, DFT or similar kinds of Transforms exhibit the property of Orthogonality. Due to this property, they are used in the Forward process in Encoder and Inverse process in the Decoder, interchangeably.

where, U is the DCT Matrix, and I is an 8x8 Identity Matrix.
where, U is the DCT Matrix, and I is an 8x8 Identity Matrix.
The DCT for a preprocessed block A, where A is 8x8 Matrix is given by,

The above form looks similar to Similarity Transform. The Similarity Transform of the Matrix A is given by,

for some Transformation Matrix Z.
Similarity Transform plays an important role in computation of Eigenvalues, because they leave the Eigenvalues of Matrix A unchanged. If A is a NxN(N=8) Matrix, we say that X is an Eigenvector and λ is the corresponding Eigenvalue of Matrix A, if

This homogeneous system can hold only if,

If expanded out, the above equation, also called the Characteristic Equation, or the Eigenvalue equation, correspond to an Nth (N=8) degree polynomial in λ, whose roots are the Eigenvalues. This proves that the Matrix A has always N(N=8) Eigenvalues and N(N=8) Eigenvectors, not necessarily distinct.
Clearly, the Eigenvalues of Matrix A remain unchanged.
Thus, based on construction of a sequence of Similarity Transforms, a Matrix decomposition of Matrix U can be performed,
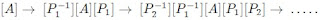
The Eigenvectors are then simply obtained as the columns of accumulated Transformations,

The Eigenvectors are then simply obtained as the columns of accumulated Transformations,
II. Fast DCT Transform
The 1-D DCT Equation is given by,


The above DCT Equation can be also written in the Matrix Form as given below,

The aim of Fast DCT is to decompose the Matrix U into Recursive form matrices, so that we can apply DCT Algorithm in a generalized way to higher order N=16, N=32, N=64 and so on. We want to decompose the DCT Matrix in the following form,
Where, the decomposition Matrices P1, P2, P3,…Pn follow the property,
So that as per Similarity Transform, the Eigenvalues of Matrix A remain unchanged. The number of stages of decomposition is related to N,
So, for N=4, we shall have 2(=log4+log1) stages of decomposition, for N=8, we shall have 4(=log8+log2) stages of decomposition, for N=16, we shall have 6 stages of decomposition and so on. Thus, for N=8, we will have,

So, for N=4, we shall have 2(=log4+log1) stages of decomposition, for N=8, we shall have 4(=log8+log2) stages of decomposition, for N=16, we shall have 6 stages of decomposition and so on. Thus, for N=8, we will have,
III. Decomposition of the DCT Matrix
Following from the last Equation,

We, see that we want to represent the DCT coefficients of Stage I decomposition, as sum and differences of the odd and even indexes of the input array x[n]. We can show this in the form of signal flow graph as follows,

The above signal flow graph operation can be represented in the form of a 8x8 Decomposition Matrix, as given below,

Let us name the above Decomposition Matrix as P1, so that this is the first stage decomposition of the DCT Matrix, and also it is very easy to see that [P1][P1]-1=[I]. Thus, what we are trying to do with DCT Matrix is as given below,

Matrix Z, can be calculated by taking an inverse of Decomposition Matrix, P1 which can be found out as follows,

The inverse of Decomposition Matrix, P1, is as given below,

So, that Matrix Z becomes,


{kind=link}
Now, if we try and relate the Matrix Z, with the DCT Matrix, we see that Matrix Z can be analyzed as being made up of two parts, Z1 and Z2

Analyzing part Z1, we see that the arrangement of the terms bear resemblance with DCT Matrix. The right half terms are mirror reflected values of the left half, for every odd numbered non-zero row. For, even non-zero row, the right half terms are negated mirror reflected values of the left half.


The above similarity can be seen in the DCT Matrix as well,

Now, since the part Z1 shows
similarity in structure with the DCT Matrix, hence the same way of
decomposition of the DCT Matrix can be applied to the part Z1 as well, albeit at
a smaller scale of 4x4, as the pairs of folded/mirrored sequences across the
left and right halves have been reduced by half. Thus the decomposition for Z1
can be shown as below,








































As, shown in one pass, we will consider the values of two rows. Thus we are calculating the DCT of two rows in one pass. Now each of the ARM NEON 128-bit Register pairs, {d0, d1}, {d2,d3}…can hold four such integer values, so {d0, d1} pair is used for this purpose to hold [0],[1],[2] and [3], and {d2, d3} pair is used to hold [4], [5], [6] and [7]. Thus {d0, d1}-{d2, d3} is used to hold one complete Row value of 8 elements. Similarly, {d4, d5}-{d6, d7} is used to hold the next complete row value of 8 elements.






The below shows the values in {d8, d9} register pair,


The below spreadsheet table shows the Trace of the above NEON vector operations and the corresponding registers involved in the operations.











Now, after this we need to prepare the Outputs in the correct order, so that they can be pushed in the DCT Array by a lane wise load, which can load a 64-bit signed value directly. As, shown below, the last part, consists of swapping and interchanging the values, so that finally we get the values in {d0,d1},{d2,d3} for the first row, and {d4,d5},{d6,d7} for the next row after that.

The Trace of the above operations can be shown on the spreadsheet as shown below, as shown the outputs of the register pairs {d0, d1},{d2, d3} contain the first row, 8-point DCT, and the register pairs {d4,d5},{d6, d7} contain the next row, 8-point DCT.

This completes the DCT along the rows. Now, we will store the result along the rows of the DCT Matrix. Observe, carefully, from the above spreadsheet how the data has been arranged in the NEON Registers {d0, d1}, {d2, d3} and {d4, d5}, {d6, d7} to complete a given DCT Row output. Clearly, register r0 shall hold the first argument of the calling C Function, which is the Input 8x8 Block Matrix’s 32-bit address, whose DCT needs to be calculated. Thus, in the beginning, we are loading two 8 row element Input 8x8 Block Matrix. Therefore, r0 shall have the address pointing towards the end of the second row. Thus, we have to start by storing from the end of the second row to beginning of the first row. This requires the r0 to be subtracted, instead of added as we were doing while loading. VST1.32 shall store two signed 32-bit integers present in its two 32-bit lanes of the 64-bit ARM NEON Register {dn, dn+1}.








[1] N. Ahmed, T. Natarajan, and K. R. Rao, Discrete Cosine Transform, IEEE. Trans. Computer, Vol C-23, pp. 90-93, Jan 1974.
[2] W.-H. Chen, C.H. Smith, and S.C. Fralick, "A Fast Algorithm for the Discrete Cosine Transform," IEEE Trans. on Communications, Vol. COM25, No. 9, Sep. 1977, pp. 1004-9. 183
[3] J C. Loeffler, A. Ligtenberg, and G. Moschytz. Practical Fast 1D DCT Algorithms With 11 Multiplications. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pages 988--991, 1989.
[4] Mircea Andrecut, “Lecture 5: Eigensystems, Similarity Transform and Jacobi Diagonalization of a Symmetric Matrix”, 2006.
[5] Kamanagar, F. A. and K. R. Rao, "Fast Algorithms for the 2-D Discrete Cosine Transform", IEEE Trans. On Computers, vol. C-31, no. 9, pp. 899-906, Sep 1982.
[6] ARM Compiler Toolchain Compiler Reference “DUI0491C_arm_compiler_reference.pdf”.
[7] ARM Compiler toolchain Using the Compiler - ARM Infocenter, “DUI0472F_using_the_arm_compiler.pdf”.
[8] The RGB Input Array Buffer
https://drive.google.com/open?id=0B6Cu_2GN5atpTXdDNkdteG9vU00
[9] The C Code Implementation of DCT & IDCT Operation,(Visual Studio, 2010)
https://drive.google.com/open?id=0B6Cu_2GN5atpeU9ESV9qTl9wTG8
[10] The Complete ARM NEON Implementation of 2D, 8x8 DCT in Assembly
https://drive.google.com/open?id=0B6Cu_2GN5atpemtsOXpsQ205cTA
[11] The ARM NEON Implementation of 2D, 8x8 DCT along Rows (Row-wise DCT)
https://drive.google.com/open?id=0B6Cu_2GN5atpS3pHMWRxNFd5QWc
[12] The ARM NEON Implementation of 2D, 8x8 DCT along Rows with Transpose(Row-wise DCT + Transpose)
https://drive.google.com/open?id=0B6Cu_2GN5atpOTIwQ3pIYUhkczQ
[13] The Makefile for the Project
https://drive.google.com/open?id=0B6Cu_2GN5atpV2xyTGJSTk9WMmc
[14] My README Notes for the Project
https://drive.google.com/open?id=0B6Cu_2GN5atpbWtNTHhPbGwyb00
[15] A Comparison Snapshot

This completes this small Project. A lot of things of importance in Image Signal Processing were delved into. A simple implementation for RaspberryPi2 was demonstrated, which proves how much powerful computing platform RaspberryPi can truly be.
Discussions can be posted in the comments section here or reach me through mail: rajiv.biswas55@gmail.com .
Thanking You,
Yours Sincerely,
Rajiv.

Now coming to the part Z2, we
cannot draw any similarity with DCT Matrix and hence the decomposition applied
for part Z1 cannot be applied for Z2. However, here we will try to see the
non-zero rows closely, on taking the non-zero rows we see that if, we take only
the magnitude of the values then this is a Symmetric Matrix, that we have in
our hand

If, we consider only the
magnitudes of the values we have a symmetric matrix, as shown below,

As, we can see for any Symmetric
Matrix, the Transpose of a Symmetric Matrix and the Matrix are same. Now, the
above matrix can be diagonalized using Jacobi Diagonalization Method which is a
sequence of Orthogonal Similarity Transform. Each Transformation is a plane
rotation designed to annihilate one of the off-diagonal elements.
The basic Jacobi Transformation is
a Matrix of the form,

Where, all the diagonal elements are unity, except the two elements c in rows p and q. All off-diagonal elements are zero except the two elements s and –s. The numbers c and s are cosine and sine of a rotation angle theta, θ,so that they satisfy the Trigonometric Identity, (cos θ)^2 + (sin θ)^2 = 1.
For the above symmetric Matrix, corresponding to Z2, the Orthogonal Transformation is given by,





For the above symmetric Matrix, corresponding to Z2, the Orthogonal Transformation is given by,

which when solved for c and s, and
equating the off-diagonal elements to zero, give us, theta, θ =pi/4.Thus, the Diagonalization matrix
is given by,

Using, the above result of
Diagonalization, for Z2 and combining it decomposition of Z1, we get the
complete second stage Decomposition matrix for the Decomposition result of
First stage as shown below,

The above decomposition Matrix can
be represented in the form of a Signal flow graph as shown below,

The Matrix T, can be found by
taking inverse of the Decomposition Matrix as shown below,

So that Matrix T becomes,

On, swapping the 2nd
row with 5th row, 4th row with 7th row, we get
the above Matrix T as shown below,

Now, the above matrix T can be
analyzed in the same way like we did previously. It can be broken into two
parts T1 and T2.

The part T1, we can divide further
into two parts. Now, its very easy to see that the upper part and the lower
parts of T1 when multiplied with their Transpose shall give us a Unity Identity
Matrix.

The part T2 can be broken down
into parts T2_1, T2_2, T2_3 and T2_4, as shown below,


we can see that, the elements of
parts T21 and T24 are diagonally mirrored/folded
images of each other. Similarly, parts T22 and T23 are negated mirrored/folded
images of each other. Since the parts T22 and T23 form a negated pair, we can
infer that the decomposition matrix will have its elements cancelled or
nullified. Thus, we can choose a similar form of decomposition Matrix having
the diagonal pairs of T21 and T24 similar and pairs T22 and T23 as zero.
The above matrix can be taken as
the decomposition for part T2. Thus combining T1 and T2 decompositions, we have
the complete decomposition matrix as follows,

On, omitting out the common term ½
out of T1 decomposition part. The above Decomposition Matrix can be represented
in the form of a Signal flow graph as shown below,

Thus, we have,

The Matrix V can be solved by
taking Inverse of the Decomposition Matrix. On solving the above and
simplifying the Trigonometric terms, we get Matrix V as,

Clearly, further decomposition to
the upper part of Matrix V is not required. The lower part can be decomposed by
taking a transpose of the same, since,


Thus, the decomposition of the
lower part is just the transpose of the same. Thus the complete decomposition
Matrix will be given by,

The above can be shown in the form
of Signal flow graph as shown below,
After this stage, no further
decomposition would be required as we are getting a Unity Identity Matrix at
this stage. This is the aim of the entire exercise of decomposition, which is
achieved at this point, and shall be the aim for any generalized form, for
N=16, 32, 64 and so on.
Thus the complete decomposition of
the DCT Matrix(N=8) is given by,


The
Complete signal flow graph is given by,
IV. Implementation of Fast DCT Transform using ARM NEON Assembly
This part provides a proof of the
concept of the above algorithm by presenting a fixed-point implementation of
the above algorithm in ARM NEON Assembly. The implementation was done on
RaspberryPi2, featuring a 1Ghz, ARM Cortex-A7 Processor. Two implementations
would be provided here, firstly a straightforward C implementation, followed by
a complex NEON Assembly implementation of the C Code. Special care is taken to
make it a complete Fixed-Point implementation.
Now, ARM NEON is a general-purpose
SIMD engine which can efficiently processes current and future multimedia
formats. NEON technology can accelerate multimedia and signal processing
algorithms such as video encode/decode, 2D/3D graphics, gaming, audio and
speech processing, image processing, telephony, and sound synthesis by at least
3x the performance of ARMv5 and at least 2x the performance of ARMv6 SIMD.
NEON technology is a 128-bit SIMD
(Single Instruction, Multiple Data) architecture extension for the ARM Cortex-A
series processors, designed to provide flexible and powerful acceleration for
consumer multimedia applications, delivering a significantly enhanced user
experience. It has 32 registers, 64-bits wide (dual view as 16 registers,
128-bits wide).
NEON instructions perform "Packed
SIMD" processing:
a. Registers are considered as vectors of elements of the same data
type.
b. Data types can be: signed/unsigned 8-bit, 16-bit, 32-bit,
64-bit, single precision floating point
c. Instructions perform the same operation in all lanes


The width x height of this image is 633 x 490 pixel. Since its a 256-bit RGB, hence each R, G and B channel comprises of values having maximum of 256 levels. On, separating the RGB Channels using the below MATLAB program and saving them in a file,”Info.bin”.

For our Analysis, we have considered only the R-Channel values. The Info.bin having only the R-Channel of the above Image is as shown below,

The number of rows of the above
data is 490 and the number of columns is 633. Let us consider a 8x8 Block, for
which we intend to find the DCT. The 8x8 Input block is as shown below,

The 8x8 DCT Algorithm will work as
follows, first the DCT will applied along the rows, following which a second
stage of DCT will be applied , along the columns, on the first stage DCT Output.

The Second stage of DCT will be
applied along the columns of the above output,

Thus, this completes the Algorithm
structure of the complete DCT Algorithm applied on 8x8 Input block.
Now, the C implementation of the
above Algorithm is quite straight forward.

The above part covers the DCT of
the above Input Matrix along the Rows. The above implementation is done in
fixed-point. The coefficients, cos(pi/16), sin(pi/16), cos(3pi/16), sin(3pi/16),
cos(3pi/8), sin(3pi/8) and sqrt(2) have been up-scaled by a factor
of 10. This has been correctly chosen so that overflow does not happen in the
subsequent operations. Now, something
interesting that has been done here is the application of a rotator block, to
reduce the number of Multiplications.

Thus, the above form reduces to
Loeffler form by introducing the Rotator block in between. Now, the number of
Multiplications required in the first case is 4 and the number of
additions/subtractions required is 2, while in the Loeffler form its is 3
multiplications and the number of additions/subtractions required is 3, (since s1+c1 and s1−c1 are constant values and thus need
not be calculated, but used directly by pre-calculating them and saving them in
some ‘#define’ constants.
Finally, in stage 4, the proper
downscaling has been done by factors of 10 and 17, as √2 has been scaled by a factor of
7. This completes the Row DCT part.
Now, next after that, we need to
apply the DCT along the columns of the above DCT Row output.

As, we can see that we are reading
the values along the columns. Now one thing is very clear from the above, the
Stage 1, Stage 2 and Stage 3 are same as the Row-wise DCT. The, only difference
is that the inputs to the DCT are read along the Columns instead of along the
Rows.
Thus, we can use the same assembly
code for calculating the DCT along the columns too. We can take the DCT along
the Rows, Transpose the output, again apply the DCT along the Rows, and finally
Transpose to get the final Output.
We will see here, four parts in
which the above C Code will be implemented in ARM NEON Assembly. In the first part
the Assembly Code will cover only the DCT along the Rows. The second part will
see, the DCT along the Rows, and the subsequent transpose applied to the
Output. The third part will see, the DCT along the Rows, with Transpose applied
after that, followed by a DCT applied to the Transpose. Finally the fourth part
will see, the DCT along the Rows, with Transpose applied after that, followed
by a DCT applied to the Transpose Matrix, and finally a Transpose applied to
bring the outputs along the columns.

Now, some analysis of the above
Assembly Code. To begin with, the Input to the Assembly routine is a C function
call with the input 8x8 Block values. Lets consider each element of the row as an
Integer value, so that we can account for all the processing that will take, as
all the coefficients have been scaled by factors of 2^10. Due to this a 32-bit
holding element is considered in the form of an Integer.

As, shown in one pass, we will consider the values of two rows. Thus we are calculating the DCT of two rows in one pass. Now each of the ARM NEON 128-bit Register pairs, {d0, d1}, {d2,d3}…can hold four such integer values, so {d0, d1} pair is used for this purpose to hold [0],[1],[2] and [3], and {d2, d3} pair is used to hold [4], [5], [6] and [7]. Thus {d0, d1}-{d2, d3} is used to hold one complete Row value of 8 elements. Similarly, {d4, d5}-{d6, d7} is used to hold the next complete row value of 8 elements.

As, shown above, we are debugging
the above Assembly by preparing the above following spreadsheet, to keep a
track of the values of every operation taking place in the NEON registers. The
above spreadsheet snap shows us the values of the operations during Stage 1.

{d0, d1}, {d4, d5} holds the sum
values of rows 1 and 2 and {d2, d3}, {d6, d7} holds the difference values of
rows 1 and 2.The following lines of code after this does this, to prepare for
the next stage.

The Instruction VREV64.32 operates
on the 64-bit register and swaps the lane of the integers. We swap the 64-bit
pairs, after that, using {d20, d21} as the temporary pair to store the values.
In the second stage we see, we
first reverse swap the 64-bit registers d5 and d0, and since we need the same
values to do the sum and differences, we save a copy of ([6] | [5]) and ([8’] |
[7’]) in {d8, d9} register pairs. After that, we do two lane 32-bit signed integer
add and two lane 32-bit signed integer subtract using VADD and VSUB. Only one
Add, is used to do two additions and one Sub, for two subtractions, for each
row. This completes stage 1 operation.

The debugging on the spreadsheet
to trace the operations above is listed in the spreadsheet below,

After,
this we take the values of s1 (200 /*sin(pi/16)<<10 span="">) and s3(569
/*sin(3pi/16)<<10 span="">) and store them in register d8. Similarly, we take
the values of c3 and c1(851 /*cos(3pi/16)<<10 span="">and 1004
/*cos(pi/16)<<10 span="">) and store it in register d9.

The below shows the values in {d8, d9} register pair,
Next, we try to multiply the
terms, two lane signed multiplications across 32-bit and 16-bit constants, to
give 32-bit product pairs in each 64-bit registers. After that, we do signed
additions and subtractions between them, using VADD and VSUB. We use VREV to
swap and position the 32-bit values in
the registers, so that the additions and subtractions are correct between the
intended pairs only.

The below spreadsheet table shows the Trace of the above NEON vector operations and the corresponding registers involved in the operations.

This completes stage 2 operation.
Now, coming to the analysis of Stage 3, we see that the stage 3, opens with the
following piece,

Here, we are using Horizontal signed
Integer Addition using the instruction VPADD.I32, and using a new instruction
VZIP.32 which will swap the lower half 32-bit lanes between two 64-bit NEON
registers. The output trace of the above operations is as shown in the
spreadsheet below,

After, this we see that we are
readying the sum and difference coefficients. Next, we will have to ready the
product coefficients, as shown in the code below,

By using careful use of VZIP.32
and VREV64.32 we are able to bring the NEON Register pair {d16, d17} to hold
the coefficients of {[6], [4]} and {[6’], [4’]} of row ‘x’ and row ‘x+1’.The
below trace of the NEON Registers on the spreadsheet try and capture the output
of the above operations,

Next, we have to ready the
multiplier constants in the 64-bit NEON Registers that are to be multiplied
with the above 64-bit NEON registers holding the coefficients.

A very interesting instruction has
been used here, which is VNEG.S32, which will do a signed negation of the
values in the two 32-bit lanes in a 64-bit NEON Register. We see, here how we
are handling the Multiplier constants of the 3rd Stage, r2c6(/*sqrt(2)*cos(3pi/8)<<10 span="">
and r2s6(1337).Thus,
what we have here are the multiplier constants placed in the order of their
signs in the register pair {d8, d9}, as shown in the spreadsheet below,
Now, we can do 16-bit and 32-bit
multiplications between the coefficients and the multiplier constants, along
the two 32-bit lanes of 64-bit NEON Registers using VMUL.I32, followed

The below
spreadsheet trace shows the outputs of the NEON Registers for the above
assembly operations, see how the signed horizontal addition instruction,
VPADD.I32 is used to calculate the horizontal sum and the difference since, we
know that a+(-b)=a-b, thus the negated
multiplier when multiplied with coefficients gives negated products, which when
added gives the differences, as understood.

This, completes the Third Stage.
Now, coming to the Fourth stage, we see the down-scaling taking place by
appropriate factors, in this case by 2^10 and 2^17(2^10 x 2^7).

The Trace of the Register outputs
for the above operations can be shown in the form of below spreadsheet, as
given below,

Now, after this we need to prepare the Outputs in the correct order, so that they can be pushed in the DCT Array by a lane wise load, which can load a 64-bit signed value directly. As, shown below, the last part, consists of swapping and interchanging the values, so that finally we get the values in {d0,d1},{d2,d3} for the first row, and {d4,d5},{d6,d7} for the next row after that.

The Trace of the above operations can be shown on the spreadsheet as shown below, as shown the outputs of the register pairs {d0, d1},{d2, d3} contain the first row, 8-point DCT, and the register pairs {d4,d5},{d6, d7} contain the next row, 8-point DCT.

This completes the DCT along the rows. Now, we will store the result along the rows of the DCT Matrix. Observe, carefully, from the above spreadsheet how the data has been arranged in the NEON Registers {d0, d1}, {d2, d3} and {d4, d5}, {d6, d7} to complete a given DCT Row output. Clearly, register r0 shall hold the first argument of the calling C Function, which is the Input 8x8 Block Matrix’s 32-bit address, whose DCT needs to be calculated. Thus, in the beginning, we are loading two 8 row element Input 8x8 Block Matrix. Therefore, r0 shall have the address pointing towards the end of the second row. Thus, we have to start by storing from the end of the second row to beginning of the first row. This requires the r0 to be subtracted, instead of added as we were doing while loading. VST1.32 shall store two signed 32-bit integers present in its two 32-bit lanes of the 64-bit ARM NEON Register {dn, dn+1}.

The below
spreadsheet shows the Store operation in the DCT Input Matrix Block 8x8 array.
Now, we need to run the entire
stages of the above process for four times, two rows of Input 8x8 Block matrix
processed in each pass. So 4 passes are required to cover the 8 rows. We will
use r4 for that purpose. Below code shows the required

As, shown r4, counter is loaded
with 4 in the beginning. We decrement it, and compare with 0, and if its not
zero, then branch to Label 1, otherwise branch to Label 2 and end the Program.
This, completes the Row DCT of a 8x8 DCT Matrix.
The below shows the Makefile
required to build the ARM NEON binary.

To, build the project, we have to
issue the command,
#make DCT
As, we can see above, the compiler
and assembler used for compiling, assembling and linking on RaspberryPi2 was
‘arm-linux-gnueabihf-’ toolchain. There was no cross-compilation involved in
any part of the project.
The Program was debugged using
GDB. GDB was employed in the GUI Mode, using the command,
#gdb –tui
#gdb –tui DCT
The GDB Commands like breakpoint,
run, next, continue, step-in and print were used extensively for debugging. Commands
like ‘info-all-registers’ were used to check the values in the ARM NEON
Registers of RaspberryPi2.
The below screenshot from
RaspberryPi2 shows an instance of Debugging using GDB.

The ARM NEON Assembly in ‘DCT.s’
file is also debugged as shown below,

The ARM General registers and NEON
Registers can be viewed using the GDB Command ‘info all-registers’, and the
value of the Input Matrix 8x8 block can be seen by using the command,
‘p
*dctBlock@8’
#info all-registers
#p *dctBlock@8
The below screen shot shows the
same,

The below image shows the setup of
RaspberryPi2 along with the connected peripherals like Keyboard, mouse et al
used, while developing this Project,

This completes our discussion, here. A
further section will be added showing how much performance can be improved from
using just the plain C Code and how much optimized still today, the hand
written assembly is.
The Complete 2D 8x8 DCT code has
been given in the Resources section at the end. The explanation more or less
follows the same like the way we analyzed and implemented the Row wise DCT,
except the Transpose part, which I leave it upon the user as an exercise, to
analyze it and get a feel of how its implemented in pure ARM NEON Assembly.
V. Resources
[1] N. Ahmed, T. Natarajan, and K. R. Rao, Discrete Cosine Transform, IEEE. Trans. Computer, Vol C-23, pp. 90-93, Jan 1974.
[2] W.-H. Chen, C.H. Smith, and S.C. Fralick, "A Fast Algorithm for the Discrete Cosine Transform," IEEE Trans. on Communications, Vol. COM25, No. 9, Sep. 1977, pp. 1004-9. 183
[3] J C. Loeffler, A. Ligtenberg, and G. Moschytz. Practical Fast 1D DCT Algorithms With 11 Multiplications. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, pages 988--991, 1989.
[4] Mircea Andrecut, “Lecture 5: Eigensystems, Similarity Transform and Jacobi Diagonalization of a Symmetric Matrix”, 2006.
[5] Kamanagar, F. A. and K. R. Rao, "Fast Algorithms for the 2-D Discrete Cosine Transform", IEEE Trans. On Computers, vol. C-31, no. 9, pp. 899-906, Sep 1982.
[6] ARM Compiler Toolchain Compiler Reference “DUI0491C_arm_compiler_reference.pdf”.
[7] ARM Compiler toolchain Using the Compiler - ARM Infocenter, “DUI0472F_using_the_arm_compiler.pdf”.
[8] The RGB Input Array Buffer
https://drive.google.com/open?id=0B6Cu_2GN5atpTXdDNkdteG9vU00
[9] The C Code Implementation of DCT & IDCT Operation,(Visual Studio, 2010)
https://drive.google.com/open?id=0B6Cu_2GN5atpeU9ESV9qTl9wTG8
[10] The Complete ARM NEON Implementation of 2D, 8x8 DCT in Assembly
https://drive.google.com/open?id=0B6Cu_2GN5atpemtsOXpsQ205cTA
[11] The ARM NEON Implementation of 2D, 8x8 DCT along Rows (Row-wise DCT)
https://drive.google.com/open?id=0B6Cu_2GN5atpS3pHMWRxNFd5QWc
[12] The ARM NEON Implementation of 2D, 8x8 DCT along Rows with Transpose(Row-wise DCT + Transpose)
https://drive.google.com/open?id=0B6Cu_2GN5atpOTIwQ3pIYUhkczQ
[13] The Makefile for the Project
https://drive.google.com/open?id=0B6Cu_2GN5atpV2xyTGJSTk9WMmc
[14] My README Notes for the Project
https://drive.google.com/open?id=0B6Cu_2GN5atpbWtNTHhPbGwyb00
[15] A Comparison Snapshot

This completes this small Project. A lot of things of importance in Image Signal Processing were delved into. A simple implementation for RaspberryPi2 was demonstrated, which proves how much powerful computing platform RaspberryPi can truly be.
Discussions can be posted in the comments section here or reach me through mail: rajiv.biswas55@gmail.com .
Thanking You,
Yours Sincerely,
Rajiv.
No comments:
Post a Comment